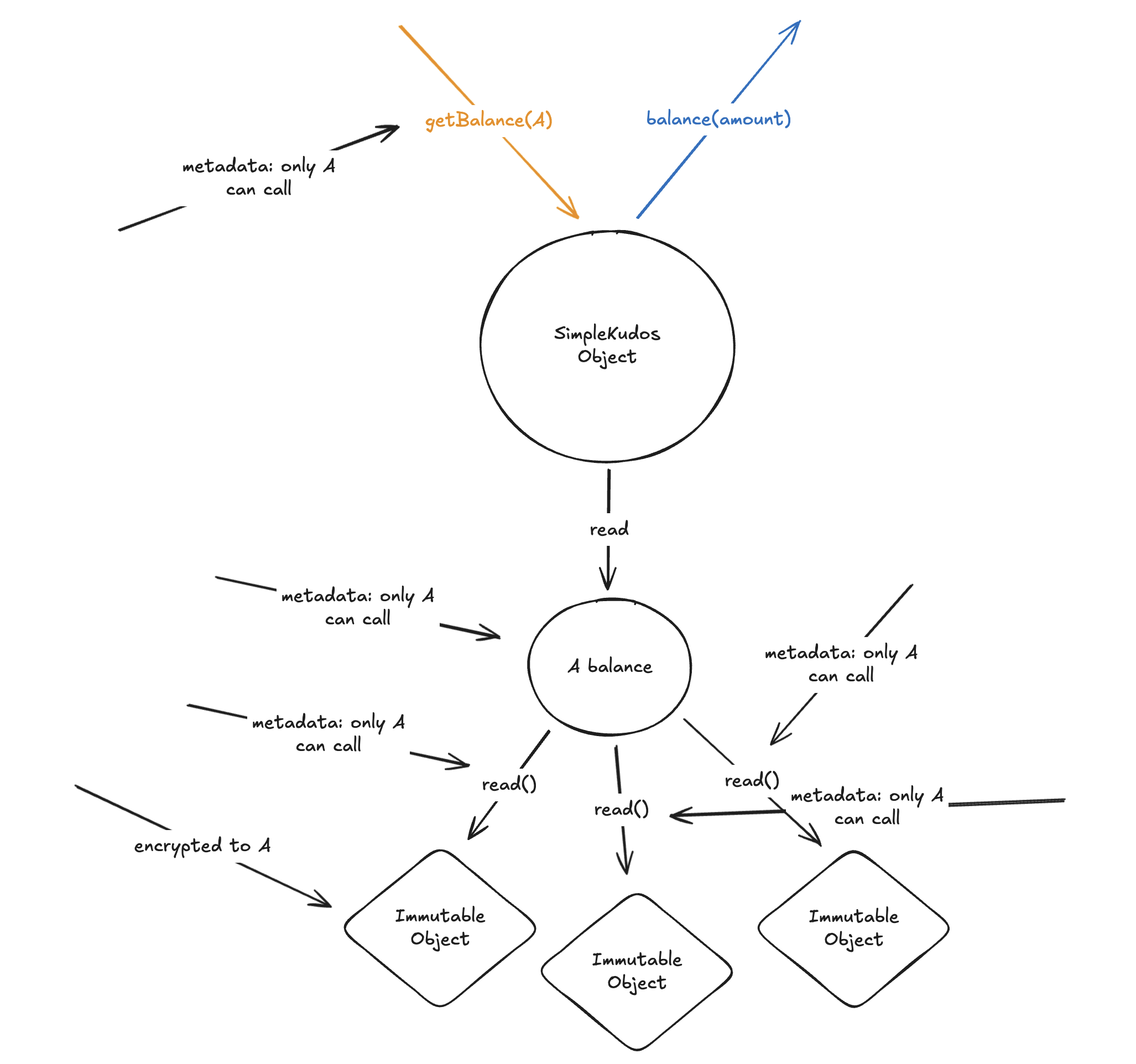
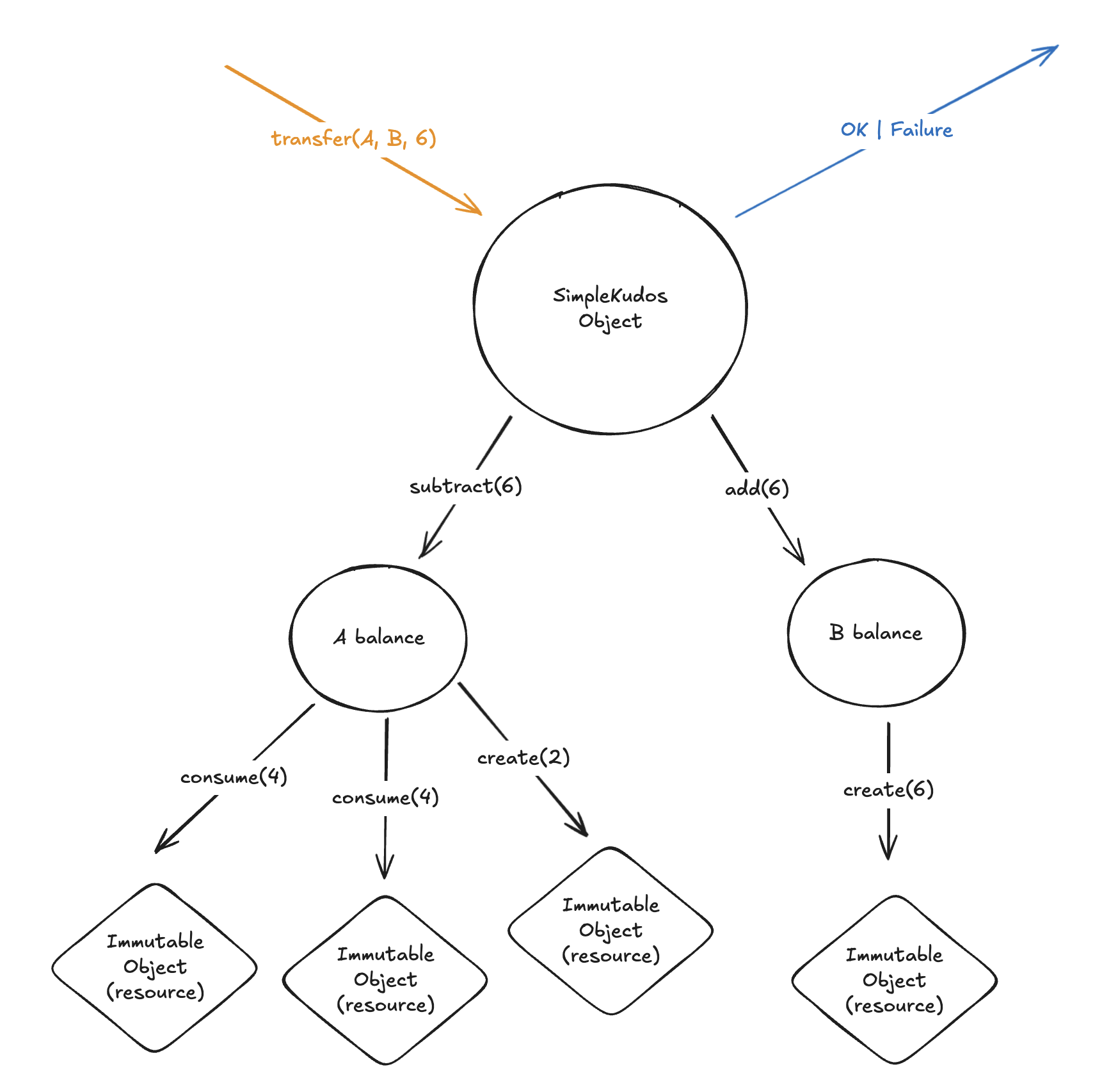
If you wonder why we do not only consider access control, note that a “practical system needs both access and flow control to satisfy all security requirements”[1]. Thus, we naturally will be lead to information flow control once we start thinking about access control.
In this post, let us focus on a concept that is shared between access control and information flow control. Looking on Wikipedia, we find lattice-based access control as a natural starting point; in particular, we have a lattice of security classes. Evidently, more than four decades later, a lot of research has been done. However, let us go back to the 70ies to get a feeling for the lattice-based approach.
One kind of access control mechanism
Denning introduces flow models for objects (in a set N), processes (in a set P), security classes (in a set SC), which come with a suitable operator for combining classes (written \oplus); most notably, we have a flow relation, modelling the allowed flow of information, in particular “direct” access, denoted \to. Thus, a full information flow model is a 5-tuple.
Denning explains this model in one short paragraph, showing how it related to access control, referencing two pre-existing approaches to access control (from the early days of computer science).
In both the Case system [22] and the MITRE system [2], each process p has an associated clearance class \underline{\smash p} specifying the highest class p can read from (observe) and the lowest class p can write into (modify or extend). Security is enforced by a run-time mechanism that permits p to acquire read access to an object a only if \underline a \to \underline{\smash p}, and write access to an object b only if \underline{\smash p} \to \underline b. Hence, p can read from a_1,\ldots, a_m and write into b_,\ldots , b_n only if \underline a_1 \oplus \ldots \oplus \underline a_m \to \underline{\smash p} \to \underline b_1 \otimes \ldots \otimes \underline b_n,. This mechanism automatically guarantees the security of all flows, explicit or implicit, since no flow from an object a to an object b can occur unless \underline{\smash a} \to \underline{\smash p} \to \underline b, which implies \underline a \to \underline b.
Here, we see that the lattice of security classes is distinct from the set of processes. In fact, all information flow information congregate into a unifying lattice of IFC labels.
What next?
One of the many advances is the unification of all information flow information into a a unifying lattice[2] This is where we shall continue in follow up posts. Finally, developers and user will benefit from good languages for expressing access control and information flow policies (see, e.g., SecureUML). Then there are questions of how we can “lift” access control from single method invocations to hierarchical transactions while avoiding side-channels.
Last, but not least: comments and questions are more than welcome!
References
- Model driven security: from UML models to access control infrastructures
- A Lattice Model of Secure Information Flow
- Flow-Limited Authorization
- SecureUML
This quote is from Denning’s paper A Lattice Model of Secure Information Flow. ↩︎
In particular, § 3.5.2 describes how access control is captured. ↩︎