This post contains some thoughts on the relationship between object behaviour and resource behaviour and in particular the semantics of non-method calls.
An example situation in the RM realm
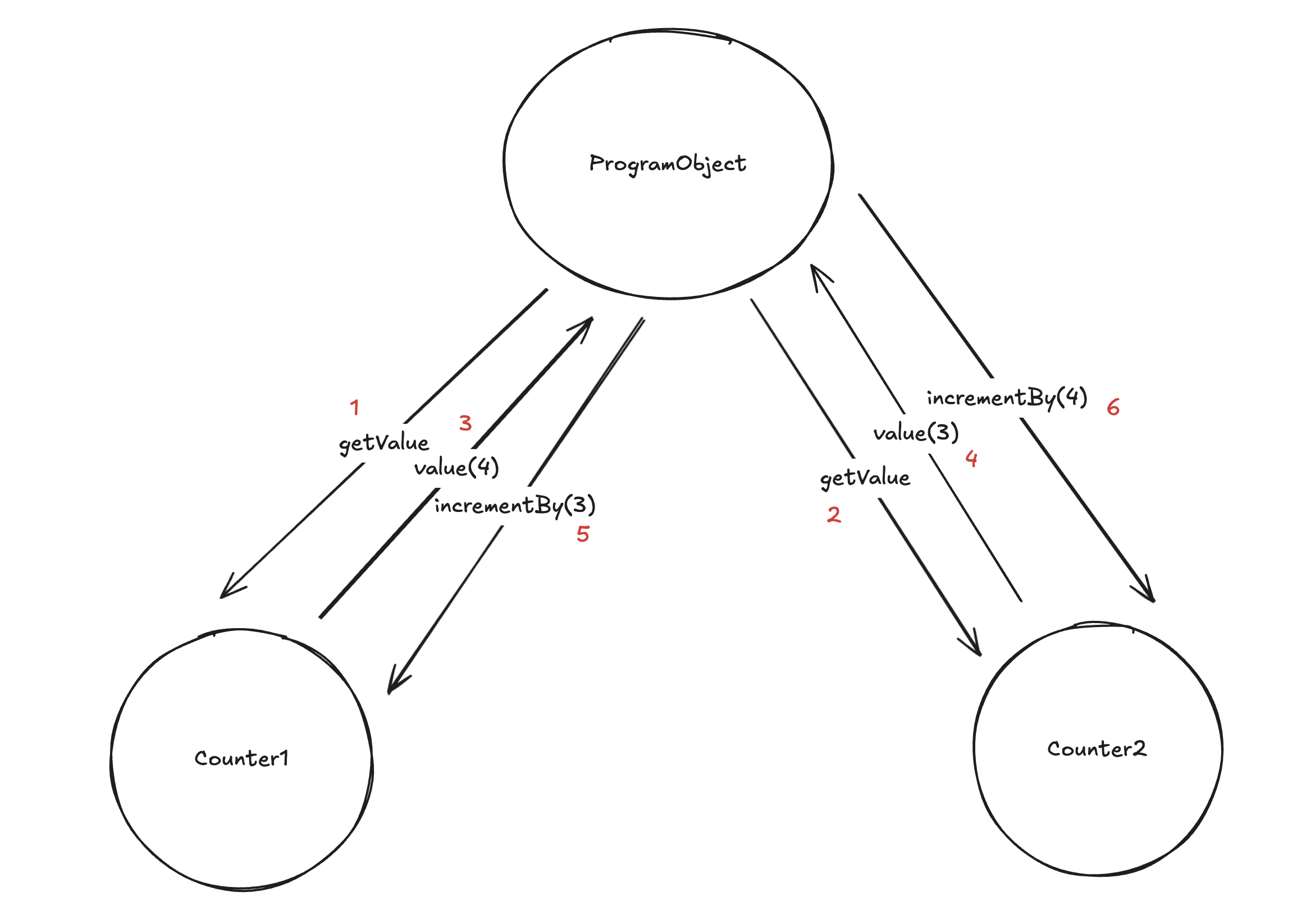
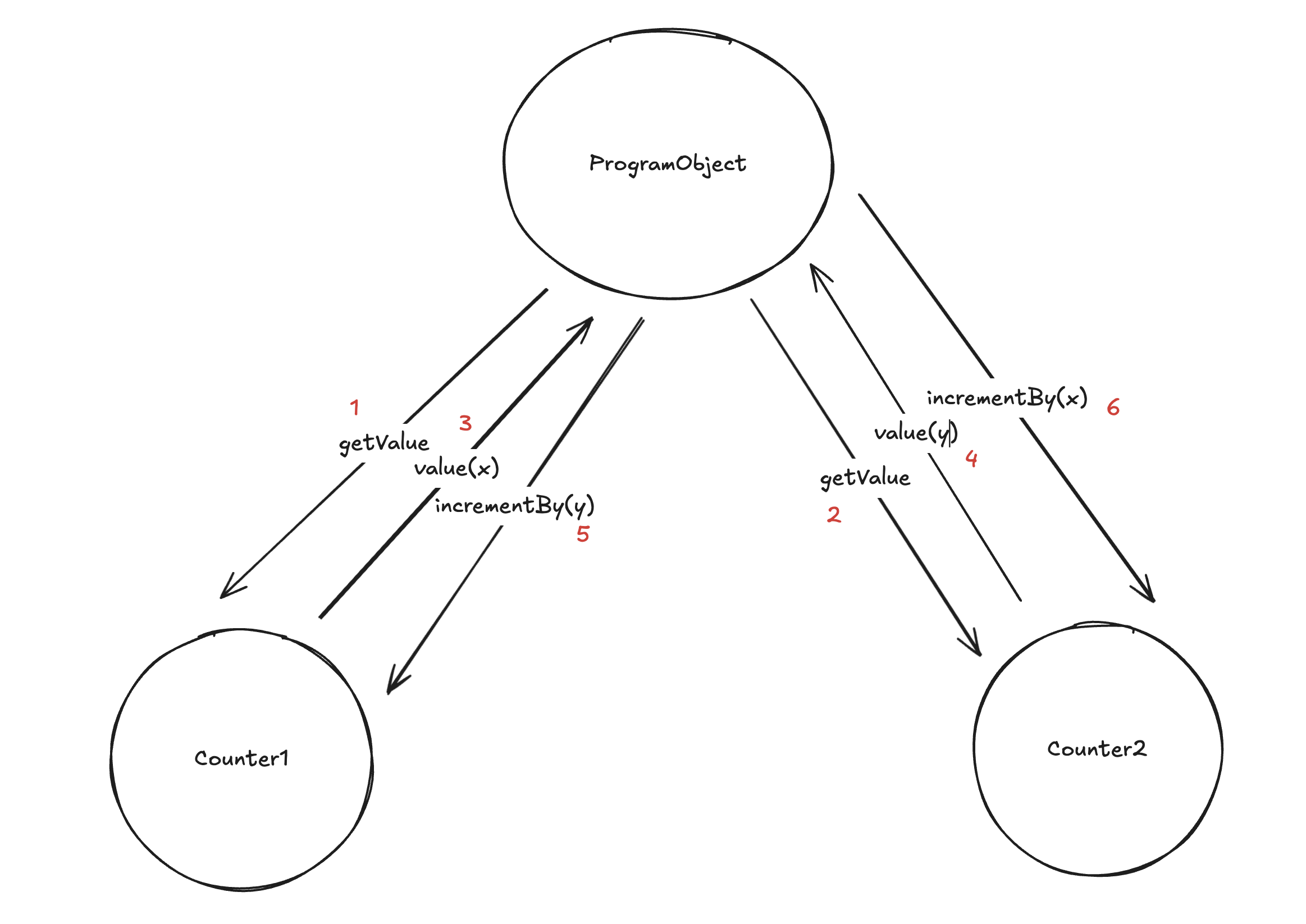
Let’s consider the following situation: imagine we have an action with a bunch of resources. We go through all resources in the action and prove their logics one by one. The logic of resource R only approves the transition if there is a corresponding resource Q in the same action. The question is: can it happen that two same kind resources Q and Q' are in the same action and only one of them is used to verify constraints of multiple resources instead of each corresponding to the designated case?
It shouldn’t be, but it isn’t clearly specified right now how to prevent this. So far it has only been done “manually”.
- Often it isn’t possible because this is wrong on the application logic level, like in the example of the counter.
- If a specific resource
Qis intended to be the counterparty for a certain constraint aboutR, we might want to have an additional logic that ensures the correspondence (if we don’t want to encode the relationship betweenRandQin eitherRorQexplicitly).
- If a specific resource
- If the resources don’t influence each other, they can be in different actions.
- The third case would be that some resources should be in the same action and they have the same kind, so the ordering question happens. I cannot think of an example when this is needed, but I cannot guarantee it is never the case.
- In this case though, we don’t really care about the order as long as the same resource is not assumed to correspond to multiple consumed ones. So the question reduces to: how to prevent the resolution in which the same resource corresponds to different ones (and who performs this)? Can the user cheat and create wrong bindings when creating the proofs?
How it relates to non-method calls
First, by non-method calls here we mean the functions that do not directly compile into resource logics. This differentiation is helpful on the RM level, even though it might be meaningless on the object language level.
In some sense, if two objects are in the same non-method, these values are related and share some scope and it might make sense to compile them into a single action. But then we might end up in the situation described in the example above. On the other hand, languages allows us calling functions from other functions as many times as we want, and obviously higher level ones cannot be actions if the lower-level ones are. So to say that non-method functions always compile to actions is wrong.
The result of this post is a bunch of questions to answer:
- what should compile to actions and what should compile to transactions?
- how to determine what should go in the same action and what can / should be in different actions?
- what high-level application properties signal that something has to be unique (like counter), different kinds with different labels, what requires an extra logic to ensure some explicit correspondence?